First, Deep dive into backprop , fundamentally understand the math behind the algorithm of backprop and also how essentials like auto-diff , gradient calculation etc are implemented in ML libs like torch and such.
Step 1: First Principle’s
From first principals, using only numpy, understand the core of optimization and how neural nets came about. Traversing the historic footsteps, explain each step, both reasoning and intuition recorded in this notebook.
Colab: Notebook

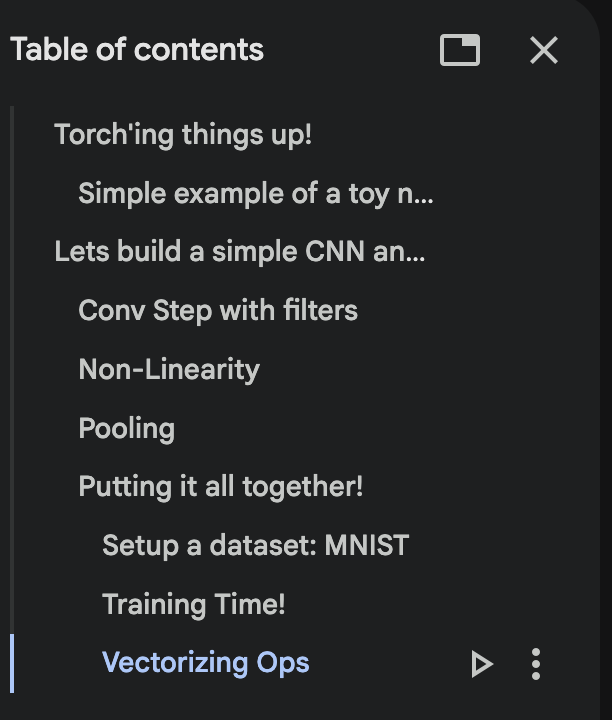
Step 2: Torch+AutoGradCNN
It would obviously be foolish to continue to use np for everything since the goal is to not just learn things conceptually but also become proficient with the tooling, hence torch. I start off from this article by the OG himself and we will try to use only the “autodiff” feature of torch. This strikes the perfect balance between understand nuances of a architecture and all the bells and whistles it comes with while building on top of what we already know for sure.
The notebook kicks off with building a naive conv op to build my first CNN layer, deeply understand the conv op and train it. Then when i do train it , i see that the GPU never gets used and the training is ridiculously slow! Guess what? GPU’s HATE LOOPS! To solve this we look at how torch can help us with thinks like “unfold” and take our first steps into thinking about “vectorizing” ops A.K.A , thinking about GPU friendly matrix ops instead of naively coding in torch.
Colab: Notebook
Step 3: Batch Norm’ing
Tuning myself to look beyond model and architecture and focus a bit on other controllables like data and behaviour of model activations , how grads and params change and whats the way to get the best out of them. Takes me through a good read of the paper and my notes of the same here and an exploration into visualizing internals of a model.
Colab: Notebook

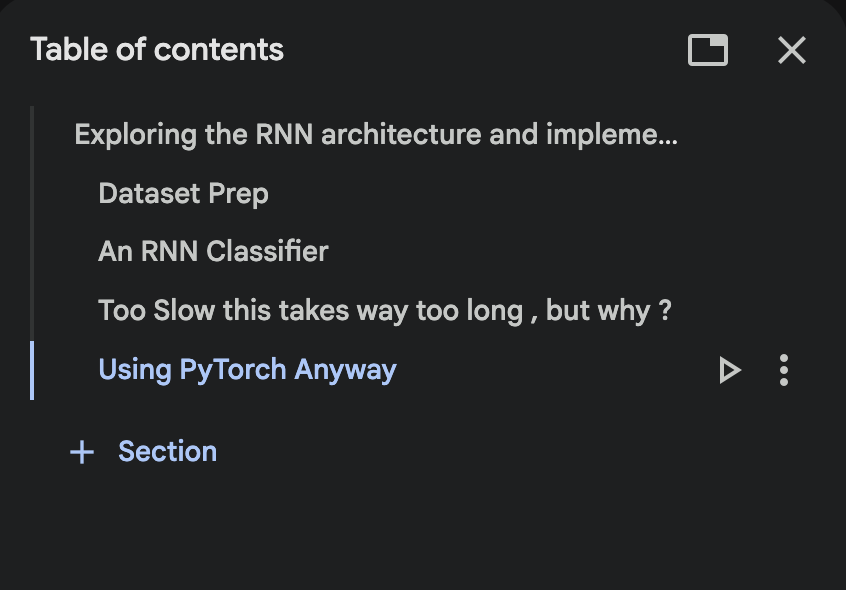
Step 4: RNN+BPTT
This topic is something that eluded me for a while, but i think i finally get what Karapathy senpai told this in his (must read for rnn) blog.

I read through this amazing article ( + my notes here) on RNNs and used it as the guide to my code.
The notebook mainly contains implementing an RNN doing BPTT using just auto-grad, understanding how “parallel” RNN training can get and building a small RNN classifier which reads “names” char by char and tries to tell us which language the name is from. I try my auto-grad only mode, get super slow model training and then go on to truly appreciate the CPP torch provides and endup using their API. Along the way I explore grad clipping, NLLLoss, playing around the mental model of different configs RNNs can operate in i.e: 1:1 , 1:many , many:1 , many:many and slowly build the mechanics to understand sequential models and auto-regressive behaviour leading up to transformers.
Colab: Notebook
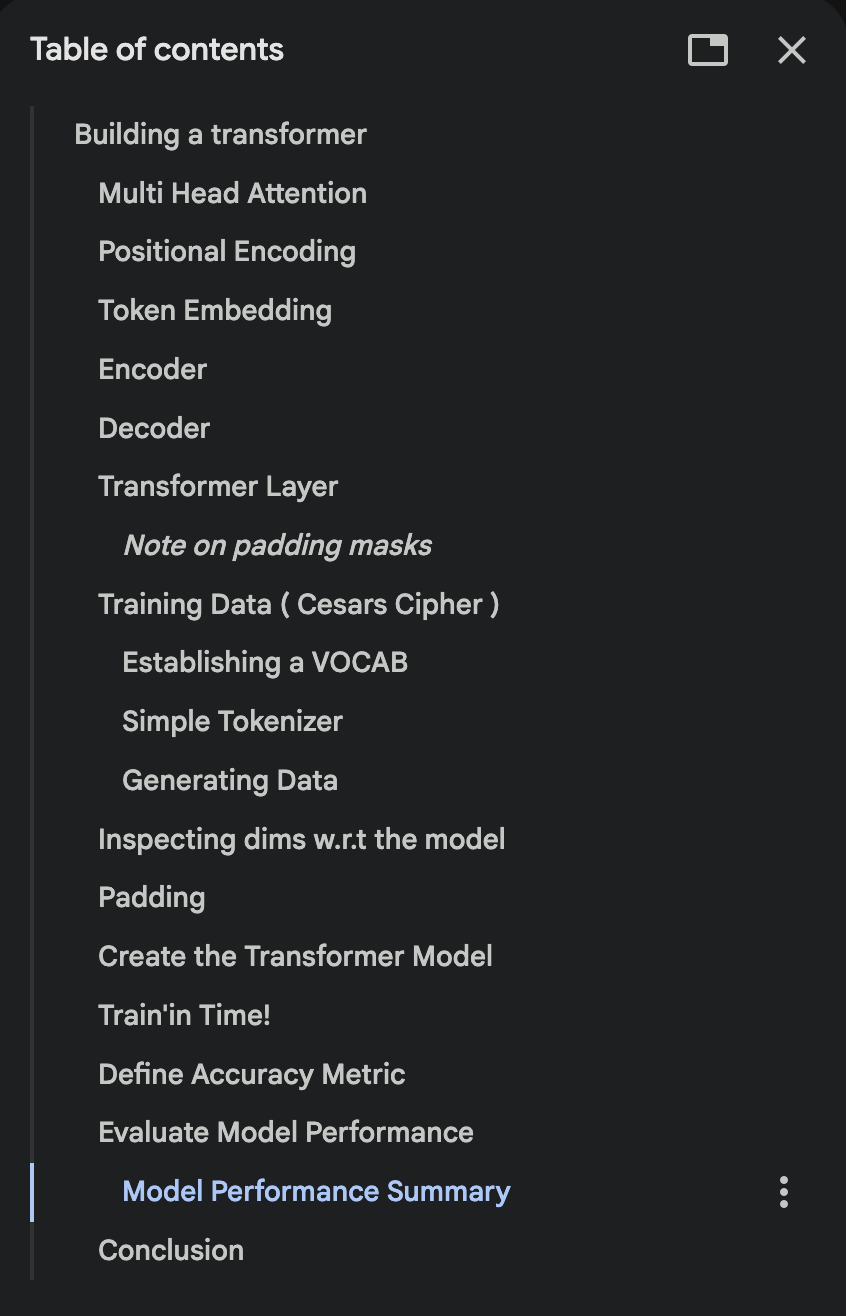
Step 5: Transformers
HAVE to start this of by read Attention is All you Need + my notes, a obviously jumping point into modern AI development. This one took a bit of time to truly understand and piece together but was worth the effort. The simple mental model is:
Attention → Multi Head Attention → Encoder → Decoder → Transformer
Again the goal of the notebook was to get to autograd only implementation which captures all the core compnents and how+why those things and are required. I literally try and code out each piece as seen in the TOC and train it on a ambitious brain-child of a dataset of my mine! Even though my model performs underwelmingly on the said task, it still demostrates the amazing learning capabilites of transformers and opens the door to important questions about data generation when randomness is involved and how much impact just improving the “representation” can have on model performance etc.
Colab: Notebook